目录结构:
1、CDN缓存
2、DNS缓存
3、本地缓存
- Cookie
- Session
- LocalStorage
- SessionStorage
4、浏览器缓存
- meta标签
- http header
CDN缓存
什么是CDN?
CDN(Content Delivery Network): 即内容分发网络
看到一个形象的比喻,来比喻CDN。
10年前,还没有火车票代售点一说,12306.cn更是无从说起。那时候火车票还只能在火车站的售票大厅购买,而我所在的小县城并不通火车,火车票都要去市里的火车站购买,而从我家到县城再到市里,来回就是4个小时车程,简直就是浪费生命。后来就好了,小县城里出现了火车票代售点,甚至乡镇上也有了代售点,可以直接在代售点购买火车票,方便了不少,全市人民再也不用在一个点苦逼的排队买票了。
CDN就可以理解为分布在每个县城或者乡镇的火车票代售点,用户在浏览网站的时候,CDN会选择一个离用户最近的CDN边缘节点来响应用户的请求,这样海南移动用户的请求就不会千里迢迢跑到北京电信机房的服务器(假设源站部署在北京电信机房)上了。
CDN的优势
- CDN节点解决了跨运营商和跨地域访问的问题,访问延时大大降低;
- 大部分请求在CDN边缘节点完成,CDN起到了分流作用,减轻了源站的负载。
CDN的工作机制
关于CDN缓存 ,在浏览器本地缓存失效后,浏览器会向CDN边缘节点发起请求。类似浏览器缓存,CDN边缘节点也存在着一套缓存机制。CDN边缘节点缓存策略因服务商不同而不同,但一般都会遵循http标准协议,通过http响应头中的Cache-control: max-age的字段来设置CDN边缘节点数据缓存时间。
当客户端向CDN节点请求数据时,CDN节点会判断缓存数据是否过期,若缓存数据并没有过期,则直接将缓存数据返回给客户端;否则,CDN节点就会向源站发出回源请求,从源站拉取最新数据,更新本地缓存,并将最新数据返回给客户端。 CDN服务商一般会提供基于文件后缀、目录多个维度来指定CDN缓存时间,为用户提供更精细化的缓存管理。
DNS缓存
什么是DNS
DNS: Domain Name System,即域名系统,负责将域名URL转化为服务器主机IP。
DNS的工作机制
DNS查找流程:首先查看浏览器缓存是否存在,不存在则访问本机DNS缓存,再不存在则访问本地DNS服务器。所以DNS也是开销,通常浏览器查找一个给定URL的IP地址要花费20-120ms,在DNS查找完成前,浏览器不能从host那里下载任何东西。
TTL(Time To Live):表示查找返回的DNS记录包含的一个存活时间,过期则这个DNS记录将被抛弃。浏览器DNS缓存也有自己的过期时间,这个时间是独立于本机DNS缓存的,相对也比较短,例如chrome只有1分钟左右。
本地缓存机制
Cookie
cookie是比较老的前端缓存技术了,它的特点是:
- 想要使用它前端必须要有服务(静态网页是不行的),而且存储大小限制在4kb
- 必须要有服务才能使用cookie,因为只要有请求涉及,cookie就要在服务器和浏览器之间来回传送。
- 由于cookie是存放在前端的,所以安全问题一直是个大问题,因此一般重要的信息不建议放在cookie中存放。
Session
对于服务端的程序员来说session大家肯定很熟悉了,session是一种服务端的机制,也就是能把信息存放在服务端,所以安全可以保障,它的原理是通过session id来识别客户端,这个session id是存放在cookie中的(当然session id让用户看见没无妨),服务端会通过session id来识别客户端进行匹配和判断。它和cookie对比起来差距就很明显了,一个是把数据存在客户端;一个存在服务端,从安全性考虑的话一般像用户名密码这种私密信息一般放在session中。
Cookie和Session简单对比
1)Cookie数据存放在客户的浏览器上,Session数据放在服务器上。
2)Cookie不是很安全,别人可以分析存放在本地的Cookie并进行Cookie欺骗,考虑到安全应当使用Session。
3)Session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能考虑到减轻服务器性能方面,应当使用Cookie。
4)单个Cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个Cookie。
5)所以建议:
- 将登陆信息等重要信息存放为Session
- 其他信息如果需要保留,可以放在Cookie中
localStorage
它的特点就是持久一旦通过保存,不通过手动清除的话,就会一直保存在前端。它能保存更大的数据(IE8上是10MB,Chrome是5MB),同时保存的数据不会再发送给服务器,避免带宽浪费。1
2
3
4
5
6
7localStorage.length //获得storage中的个数
localStorage.key(n) //获得storage中第n个元素对的键值(第一个元素是0)
localStorage.getItem(key) //获取键值key对应的值
localStorage.key //获取键值key对应的值
localStorage.setItem(key, value) //添加数据,键值为key,值为value
localStorage.removeItem(key) //移除键值为key的数据
localStorage.clear() //清除所有数据
sessionStorage
这个和localStorage有什么区别呢?sessionStorage是一种会话级别的本地存储,一旦关闭浏览器他就会消失,而前者是很持久的,即使你关闭一万次浏览器也没事,所以差距还是很大的。
1 | sessionStorage.length //获得storage中的个数 |
sessionStorage和localStorage的区别
sessionStorage用于本地存储一个会话(session)中的数据,这些数据只有在同一个会话中的页面才能访问并且当会话结束后数据也随之销毁。因此sessionStorage不是一种持久化的本地存储,仅仅是会话级别的存储。当用户关闭浏览器窗口后,数据立马会被删除。
localStorage用于持久化的本地存储,除非主动删除数据,否则数据是永远不会过期的。第二天、第二周或下一年之后,数据依然可用。
浏览器缓存
什么是浏览器缓存
简单来说,浏览器缓存就是把一个已经请求过的Web资源(如html页面,图片,js,数据等)拷贝一份副本储存在浏览器中。缓存会根据进来的请求保存输出内容的副本。当下一个请求来到的时候,如果是相同的URL,缓存会根据缓存机制决定是直接使用副本响应访问请求,还是向源服务器再次发送请求。比较常见的就是浏览器会缓存访问过网站的网页,当再次访问这个URL地址的时候,如果网页没有更新,就不会再次下载网页,而是直接使用本地缓存的网页。只有当网站明确标识资源已经更新,浏览器才会再次下载网页。
为什么使用缓存
1、减少网络带宽消耗重叠。
无论对于网站运营者或者用户,带宽都代表着金钱,过多的带宽消耗,只会便宜了网络运营商。当Web缓存副本被使用时,只会产生极小的网络流量,可以有效的降低运营成本。
2、降低服务器压力
给网络资源设定有效期之后,用户可以重复使用本地的缓存,减少对源服务器的请求,间接降低服务器的压力。同时,搜索引擎的爬虫机器人也能根据过期机制降低爬取的频率,也能有效降低服务器的压力。
3、减少网络延迟,加快页面打开速度
带宽对于个人网站运营者来说是十分重要,而对于大型的互联网公司来说,可能有时因为钱多而真的不在乎。那Web缓存还有作用吗?答案是肯定的,对于最终用户,缓存的使用能够明显加快页面打开速度,达到更好的体验。
meta标签常见以下几种用法
1、pragma与no-cache用于定义页面缓存1
<meta http-equiv="pragma" content="no-cache">
2、常见的取值有private、no-cache、max-age、must-revalidate等,默认为private1
<meta http-equiv="cache-control" content="no-cache">
3、指定Expires值为一个早已过去的时间,那么访问此网时若重复在地址栏按回车,那么每次都会重复访问1
<meta http-equiv="Expires" content="0">

http header
在介绍HTTP缓存之前,作为知识铺垫,先简单介绍一下HTTP报文
HTTP报文就是浏览器和服务器间通信时发送及响应的数据块。
浏览器向服务器请求数据,发送请求(request)报文;服务器向浏览器返回数据,返回响应(response)报文。
~~~~
报文信息主要分为两部分
- 包含属性的首部(header)————————–附加信息(cookie,缓存信息等)与缓存相关的规则信息,均包含在header中
- 包含数据的主体部分(body)———————–HTTP请求真正想要传输的部分
继续介绍缓存规则:
为方便大家理解,我们认为浏览器存在一个缓存数据库,用于存储缓存信息。
在客户端第一次请求数据时,此时缓存数据库中没有对应的缓存数据,需要请求服务器,服务器返回后,将数据存储至缓存数据库中。
HTTP缓存有多种规则,根据是否需要重新向服务器发起请求来分类,我将其分为两大类(强制缓存,对比缓存)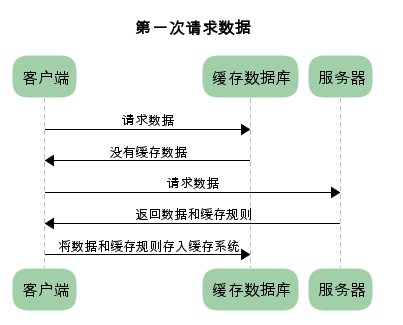
在详细介绍这两种规则之前,先通过时序图的方式,让大家对这两种规则有个简单了解。
已存在缓存数据时,仅基于强制缓存,请求数据的流程如下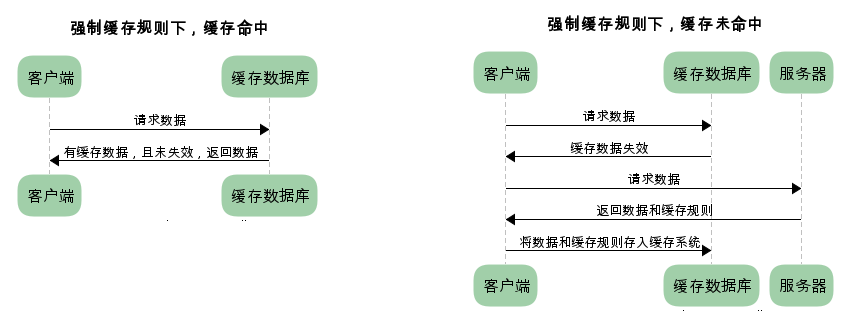
已存在缓存数据时,仅基于对比缓存,请求数据的流程如下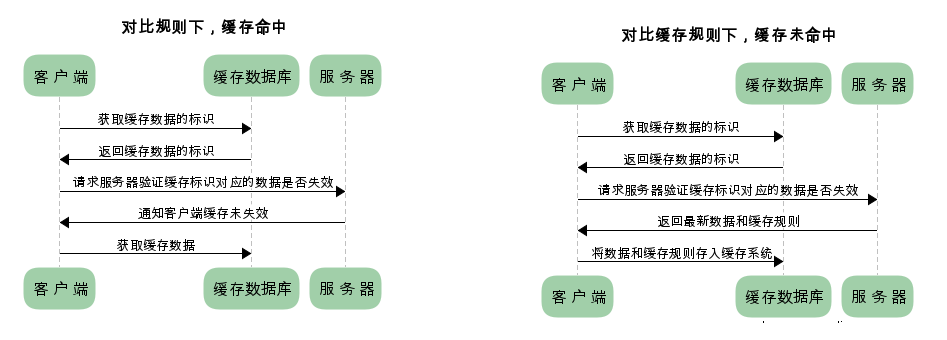
我们可以看到两类缓存规则的不同,强制缓存如果生效,不需要再和服务器发生交互,而对比缓存不管是否生效,都需要与服务端发生交互。
两类缓存规则可以同时存在,强制缓存优先级高于对比缓存,也就是说,当执行强制缓存的规则时,如果缓存生效,直接使用缓存,不再执行对比缓存规则。
强缓存与协议缓存的主要区别: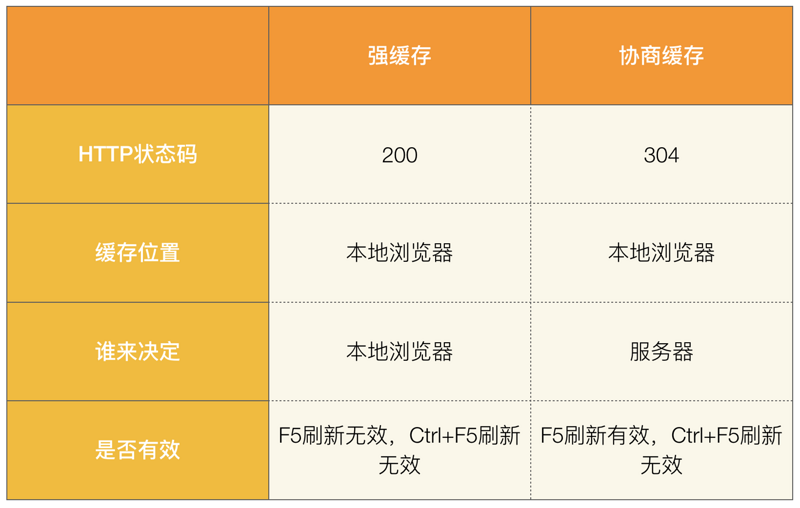
强制缓存
如何判断缓存是否失效
从上文我们得知,强制缓存,在缓存数据未失效的情况下,可以直接使用缓存数据,那么浏览器是如何判断缓存数据是否失效呢?
我们知道,在没有缓存数据的时候,浏览器向服务器请求数据时,服务器会将数据和缓存规则一并返回,缓存规则信息包含在响应header中。
对于强制缓存来说,响应header中会有两个字段来标明失效规则(Expires/Cache-Control)
使用chrome的开发者工具,可以很明显的看到对于强制缓存生效时,网络请求的情况
与缓存有关的HTTP消息报头
Expires
Expires的值为服务端返回的到期时间,即下一次请求时,请求时间小于服务端返回的到期时间,直接使用缓存数据。
不过Expires 是HTTP 1.0的东西,现在默认浏览器均默认使用HTTP 1.1,所以它的作用基本忽略。
另一个问题是,到期时间是由服务端生成的,但是客户端时间可能跟服务端时间有误差,这就会导致缓存命中的误差。
所以HTTP 1.1 的版本,使用Cache-Control替代。
Cache-Control
Cache-Control 是最重要的规则。常见的取值有private、public、no-cache、max-age,no-store,默认为private。1
2
3
4
5private: 客户端可以缓存
public: 客户端和代理服务器都可缓存(前端的同学,可以认为public和private是一样的)
max-age=xxx: 缓存的内容将在 xxx 秒后失效
no-cache: 需要使用对比缓存来验证缓存数据(后面介绍)
no-store: 所有内容都不会缓存,强制缓存,对比缓存都不会触发(对于前端开发来说,缓存越多越好,so...基本上和它说886)
举个例子: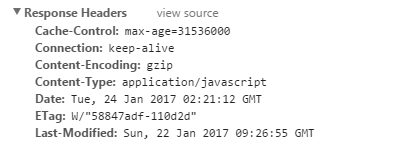
图中Cache-Control仅指定了max-age,所以默认为private,缓存时间为31536000秒(365天)
也就是说,在365天内再次请求这条数据,都会直接获取缓存数据库中的数据,直接使用。
对比缓存(协商缓存)
缓存标识如何传递
对比缓存,顾名思义,需要进行比较判断是否可以使用缓存。
浏览器第一次请求数据时,服务器会将缓存标识与数据一起返回给客户端,客户端将二者备份至缓存数据库中。
再次请求数据时,客户端将备份的缓存标识发送给服务器,服务器根据缓存标识进行判断,判断成功后,返回304状态码,通知客户端比较成功,可以使用缓存数据。
第一次访问:
再次访问:
通过两图的对比,我们可以很清楚的发现,在对比缓存生效时,状态码为304,并且报文大小和请求时间大大减少。
原因是,服务端在进行标识比较后,只返回header部分,通过状态码通知客户端使用缓存,不再需要将报文主体部分返回给客户端。
对于对比缓存来说,缓存标识的传递是我们着重需要理解的,它在请求header和响应header间进行传递,
一共分为两种标识传递,接下来,我们分开介绍。
Last-Modified/If-Modified-Since
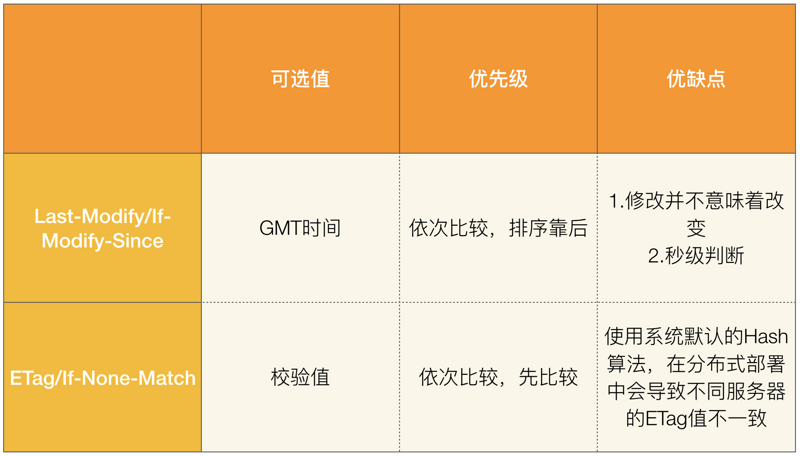
Last-Modified
服务器在响应请求时,告诉浏览器资源的最后修改时间。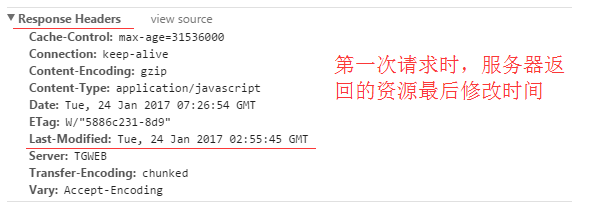
If-Modified-Since
再次请求服务器时,通过此字段通知服务器上次请求时,服务器返回的资源最后修改时间。
服务器收到请求后发现有头If-Modified-Since 则与被请求资源的最后修改时间进行比对。
若资源的最后修改时间大于If-Modified-Since,说明资源又被改动过,则响应整片资源内容,返回状态码200;
若资源的最后修改时间小于或等于If-Modified-Since,说明资源无新修改,则响应HTTP 304,告知浏览器继续使用所保存的cache。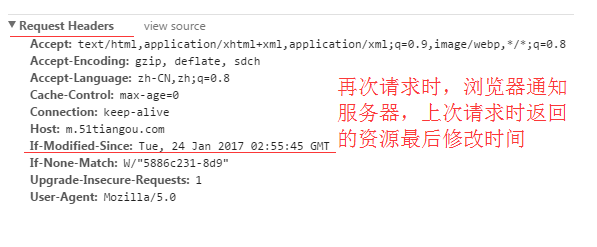
Etag/If-None-Match(优先级高于Last-Modified / If-Modified-Since)
Etag
服务器响应请求时,告诉浏览器当前资源在服务器的唯一标识(生成规则由服务器决定)。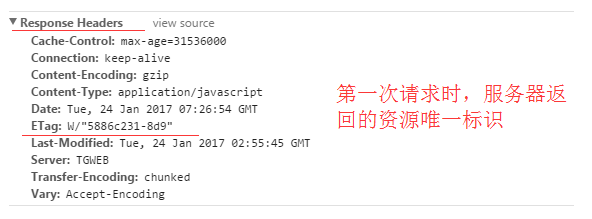
If-None-Match
再次请求服务器时,通过此字段通知服务器客户段缓存数据的唯一标识。
服务器收到请求后发现有头If-None-Match 则与被请求资源的唯一标识进行比对,
不同,说明资源又被改动过,则响应整片资源内容,返回状态码200;
相同,说明资源无新修改,则响应HTTP 304,告知浏览器继续使用所保存的cache。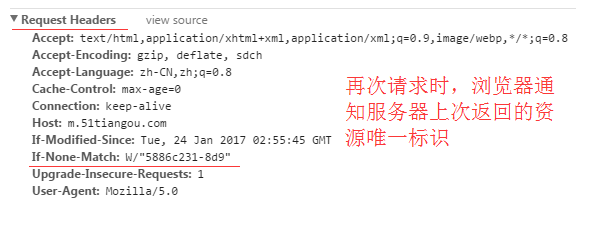
为什么有了last-modified还要有etags
- 某些服务器不能精确得到资源的最后修改时间,这样就无法通过最后修改时间判断资源是否更新
- 如果资源修改非常频繁,在秒以下的时间内进行修改,而Last-modified只能精确到秒
- 一些资源的最后修改时间改变了,但是内容没改变,使用ETag就认为资源还是没有修改的
总结强制缓存与比较缓存
对于强制缓存,服务器通知浏览器一个缓存时间,在缓存时间内,下次请求,直接用缓存,不在时间内,执行比较缓存策略。
对于比较缓存,将缓存信息中的Etag和Last-Modified通过请求发送给服务器,由服务器校验,返回304状态码时,浏览器直接使用缓存。
浏览器第一次请求: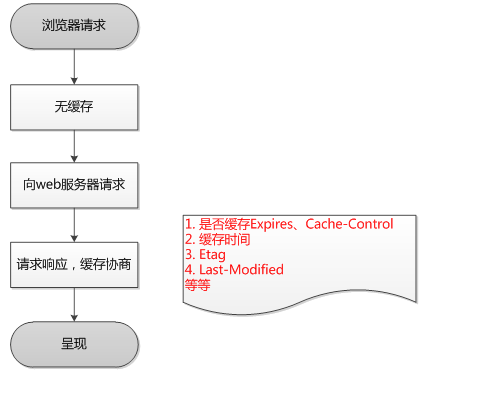
浏览器再次请求时: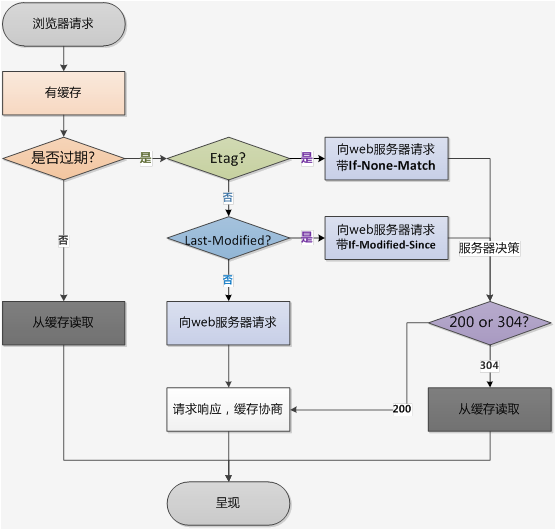
缓存储存在哪儿?
disk cache
disk cache为存储在硬盘中的缓存,存储在硬盘中的资源相对稳定,不会随着tab或浏览器的关闭而消失,可以用来存储大型的,需长久使用的资源。
当硬盘中的资源被加载时,内存中也存储了该资源,当下次改资源被调用时,会优先从memory cache中读取,加快资源的获取。
memory cache
memory cache即存储在内存中的缓存,内存中的内容会随着tab的关闭而释放。
当接口状态返回304时,资源默认存储在memory cache中,当页面关闭后,重新打开需要再次请求。
为什么有的资源一会from disk cache,一会from memory cache?
遵循三级缓存原理
- 先去内存看,如果有,直接加载
- 如果内存没有,择取硬盘获取,如果有直接加载
- 如果硬盘也没有,那么就进行网络请求
- 加载到的资源缓存到硬盘和内存,下次请求可以快速从内存中获取到
为什么有的请求状态码返回200,有的返回304?
- 200 from memory cache
不访问服务器,直接读缓存,从内存中读取缓存。此时的数据时缓存到内存中的,当关闭进程后,也就是浏览器关闭以后,数据将不存在。 - 200 from disk cache
不访问服务器,直接读缓存,从磁盘中读取缓存,当关闭进程时,数据还是存在。 - 304 Not Modified
访问服务器,发现数据没有更新,服务器返回此状态码。然后从缓存中读取数据。
推荐阅读
该文章以生动的图片形式解释了缓存,建议阅读:前端缓存
参考文章
前端几种本地缓存机制
浏览器缓存机制详解
前端性能优化之缓存利用
彻底弄懂HTTP缓存机制及原理
前端缓存机制的总结
深入理解浏览器的缓存机制
从前端角度理解缓存
一篇文章理解Web缓存
HTTP 缓存机制一二三