7.14
- 学会了使用vscode打开文件,
code demo1.html
1、安装node以及cnpm的教程
千万注意!!!打开windows终端之后默认的目录是C:/Users/hp,但是我在官网上下载的node保存在D:/Program Files/nodejs里面,设置环境变量的时候设置的是node,导致cnpm -v总出现不是内部命令的提示,实际上就是因为cnpm没有设置好环境变量!!!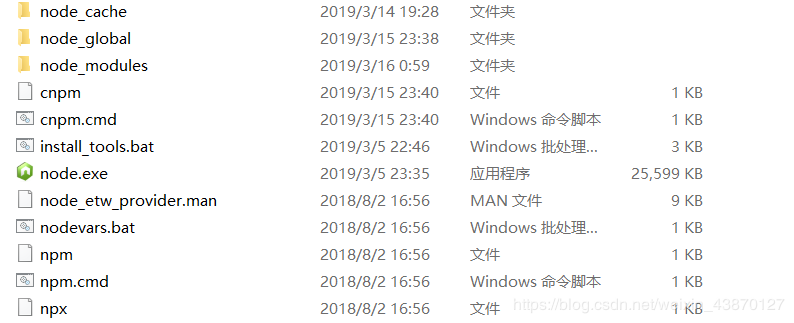
理想状态下的nodejs文件夹是这样的,保存npm和npm.cmd,以及cnpm和cnpm.cmd这两种后缀名的文件,包括我下载的别的内容也如此: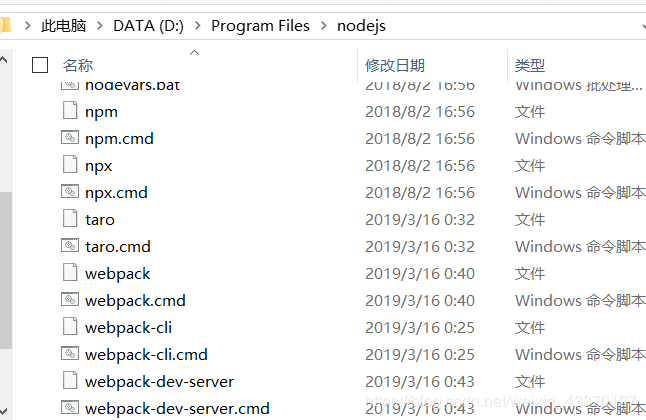
包括文件本身及其.cmd后缀文件,然后它们相应的的文件夹保存在node_modules文件夹中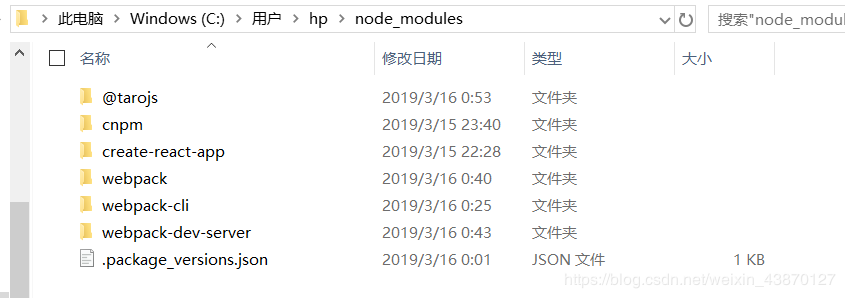
2、在把这些都搞好以后,我装了react,但是运行时它又提示webpack版本过高,所以重新下载了它要求的版本,然后继续提升webpack-dev-server版本过低,所以也重新下载了它要求的版本。然后才能够运行
3、taro的坑是无法自动安装项目依赖,安装项目依赖失败后手动安装npm install也不行,解决方法是安装cnpm
4、taro安装依赖成功后编译不成功,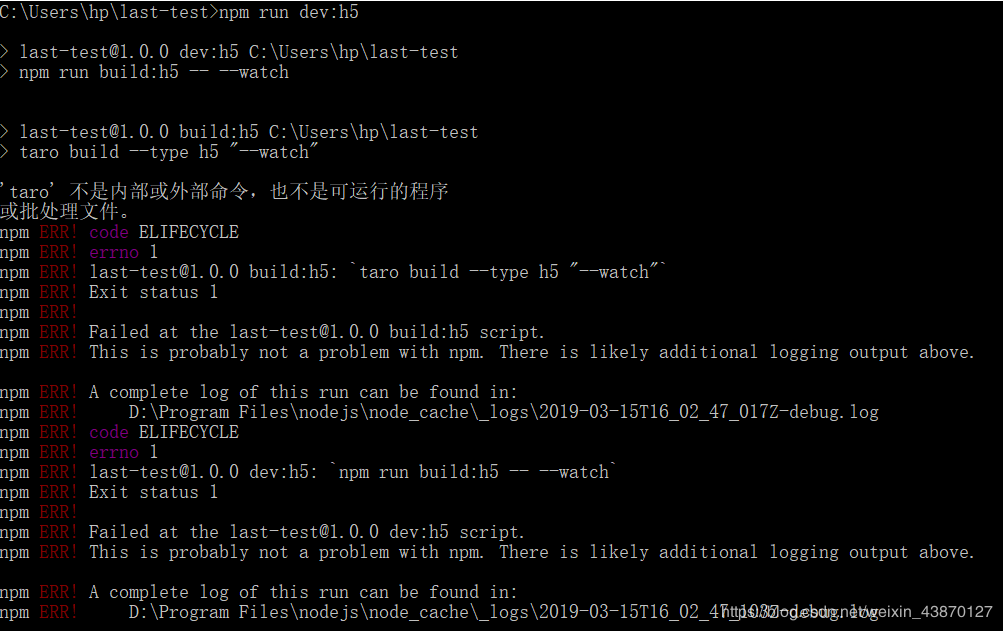
关注taro不是内部命令,由前几次安装cnpm失败可知这是taro设置全局变量不成功,所以就有了上面nodejs文件夹里的格式,再windows上安装这些东西,最大的坑就是要设置全局变量,然后设置错误啊!!!!= = 有的人不需要设置系统直接给出了,有的倒霉蛋比如我就得一个一个设置,总而言之安装上方nodejs的文件夹格式是可以设置成功的
5、taro下载依赖不成功的理由还有没有下载python,所以又跑去下载了Python,神奇的是这个不需要设置全局变量它自己给我设置好了
总结:taro其实和react安装差不多,但是可能是taro它比较新所以不完善吗???它的错误提示一点都不明确,都是一些看不懂的内容,幸亏我是react、taro一起下,出现了同样看不懂的内容,react还提示了我看得懂的内容,比如我要下载Python,比如我webpack和webpack-dev-server版本不对等等,这次在windows上安装最大的收获就是学会看错误提示了,一起看都不想看看也看不懂的内容,这次仔细瞅瞅发现还是可以看懂的,只是需要耐心。一定一定要仔细看它的错误提示!!!!它说not found在一个路径中,你就把这个文件放在它要的路径中,它说need xxx,你就下载个xxx,不要急着找教程,网上教程很可能没有你恰好遇到的问题
一个最典型的例子就是
1 | import Taro, { Component } from '@tarojs/taro'; |
当出现多个this.state.xxxx时候,可以吧this.state提出来,在函数开头写const {password, stdnum} = this.state,这样在此函数中就可直接使用password来代替this.state.password
以上为项目中最常用到的内容,有关解析结构其他内容参见文章
1 | config = { |
1 | position: absolute; |
遮罩部分的背景:1
2
3
4
5
6
7
8width: 100%;
height: 100%;
background: grey;
position: absolute;
z-index: 1000;
top: 0;
left: 0;
opacity: 0.6;
在获取点赞数的时候后端同时会返回一个布尔值,当这个布尔值为true说明我已经对该用户点过赞了,渲染的时候就渲染实心的图片,如果布尔值为flase说明未点过赞,渲染的时候渲染空心的图片
这部分较为容易,只需要发送给后端该用户的ID就可以,后端判断是否可以点赞或者取消点赞,200就成功,其他值就返回点赞/取消点赞失败
你可以通过用花括号包裹代码在 JSX 中嵌入几乎任何表达式 ,也包括 JavaScript 的逻辑与 &&,它可以方便地条件渲染一个元素。如果条件是 true,&& 右侧的元素就会被渲染,如果是 false,Taro 会忽略并跳过它。1
2
3
4
5
6
7
8
9
10
11
12class LoginStatus extends Component {
render () {
const isLoggedIn = this.props.isLoggedIn
return (
<View>
{isLoggedIn && <Text>已登录</Text>}
{!isLoggedIn && <Text>未登录</Text>}
</View>
)
}
}
1 | import Taro from "@tarojs/taro"; |
核心接口 wx.login、wx.checkSession、wx.getWeRunData
需要注意的是当前的session是否过期 wx.checkSession判断当前session是否过期,如果过期的话就重新调用登录接口,把获取到的code传给服务端,通知服务端更新session_key(前后端必须保证session_key一致才能解析成功)
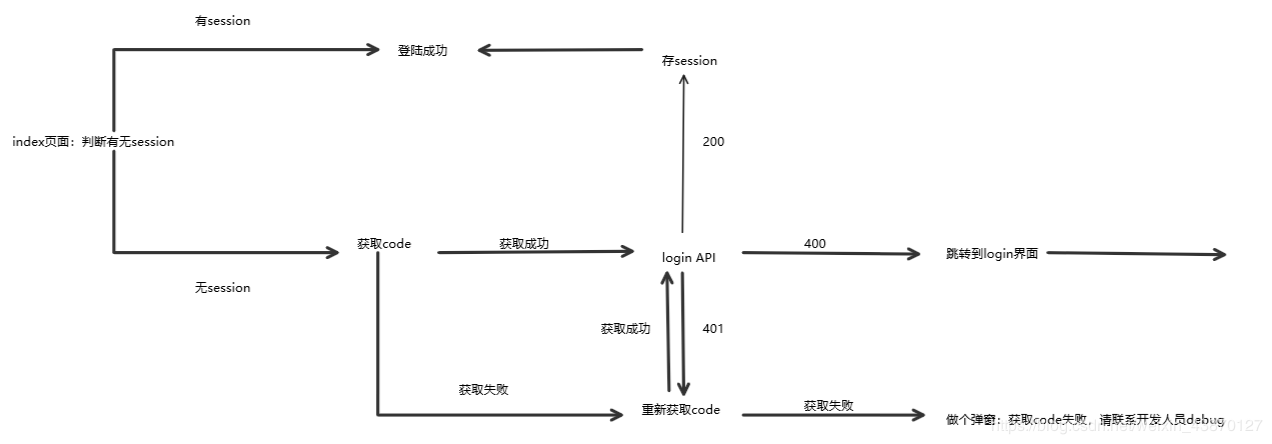
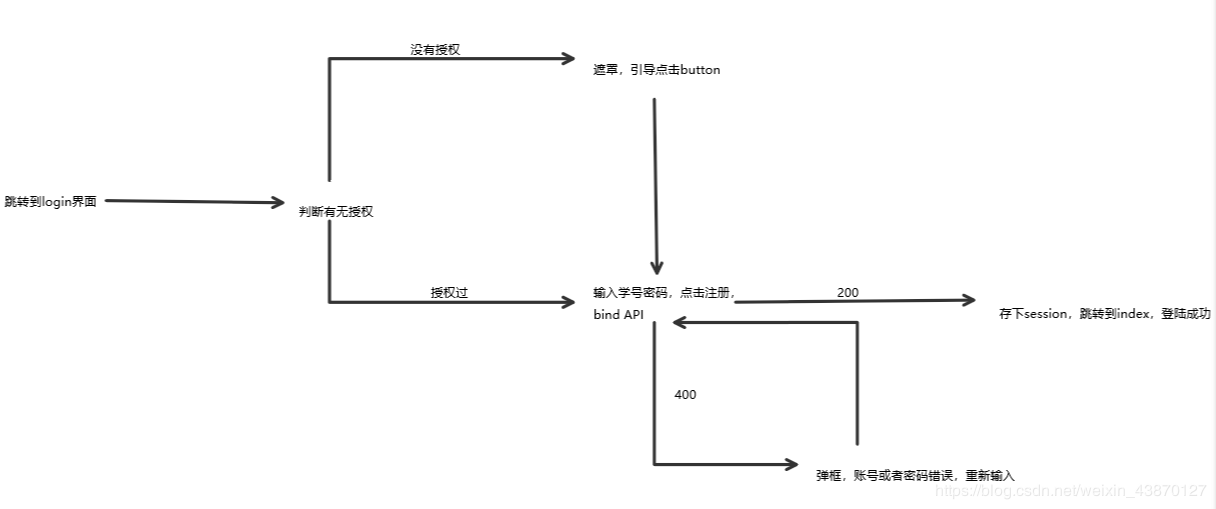
以上是最基本的登陆思路,除了以上的login页面之外,还有liblogin页面以及vistorlogin页面也存在于“登录”代码的一部分
外表与login界面相同,但是JS相关代码仅为将账号和密码发送给后端并保存在本地
这是一个游客模式下账号绑定的页面。
如果在第一次进入小程序并且点击了游客模式的同学可以在我的页面点击账号绑定进入待该页面。
外表与login界面相同,内里的JS代码和login界面也相同,只不过删除掉了授权获取用户信息的弹窗和遮罩。
在这部分遇到了很多的问题,但是详细的怎么做不是一个小标题下可以写完的,在此引申出了多篇相关的文章:
在大一下学期的学习过程中,我主要学习到的内容:
除了以上的一些大块儿内容外,还在写分享、改bug、看教程的过程中学习到了一些小的点,非常后悔的事情是在学习过程中没有随时学随时写总结,有的东西有些忘了。这篇总结可能会比较长,会努力更新完善,为自己的大一下学期做个收尾。
下面就以上学习到的内容进行总结,大部分的结构为仓库代码、环境的搭建、该框架所必备的学习到的基础知识总结、写项目的思路、遇到的问题及解决
1 | npm install -g @tarojs/cli |
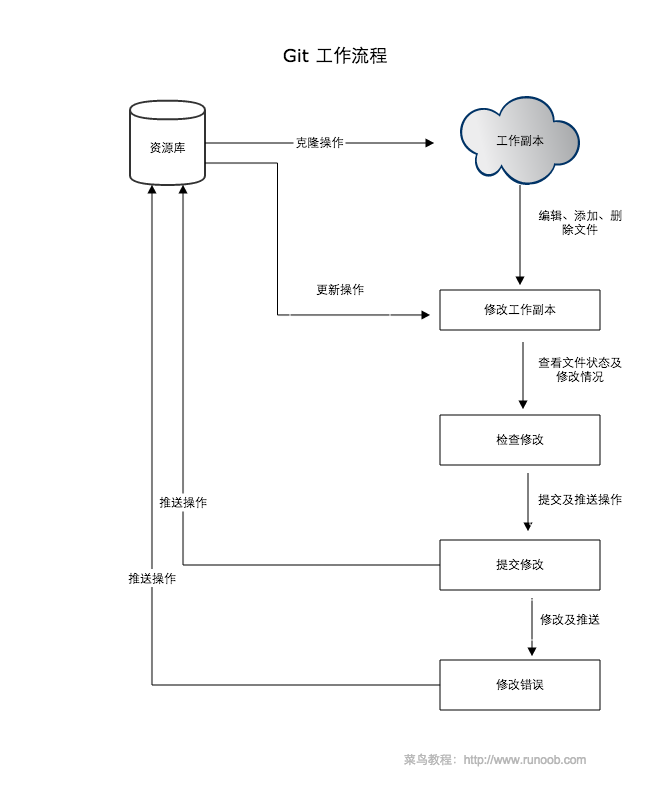
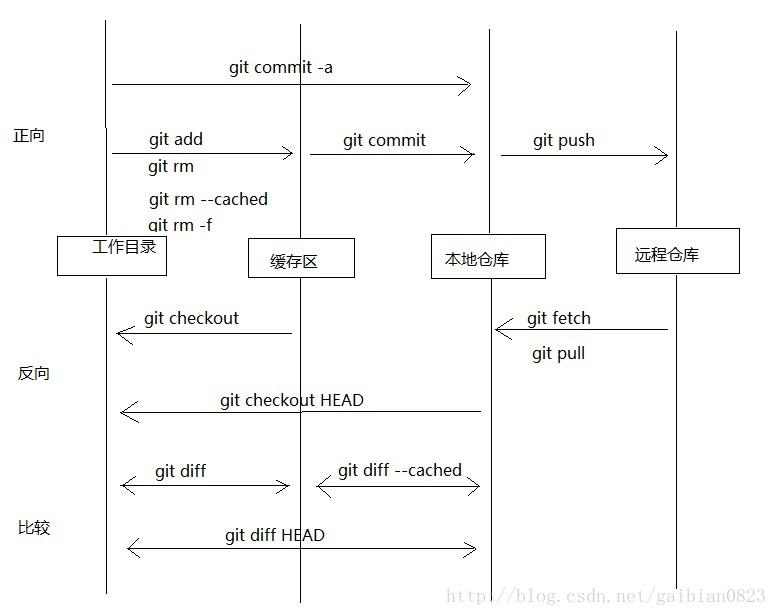
这篇文章主要介绍一下git的分支管理机制,用形象的图片来表明git的分支是如何来实现的。实际上,git分支管理机制主要依赖于指针的变化:
即创建一个指向HEAD当前指向的分支、当前版本的指针。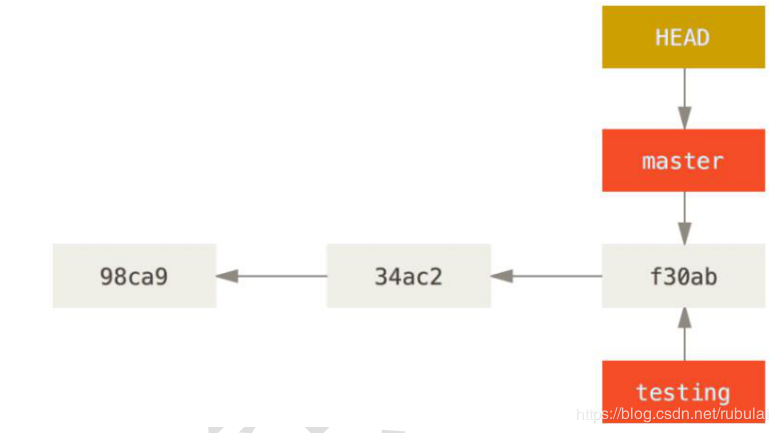
说明:此时HEAD指向master分支的f30ab版本,那么新创建的testing分支的指针也会指向master分支的f30ab版本,实际上是创建的分支的指针会指向HEAD指针指向的分支所在的版本
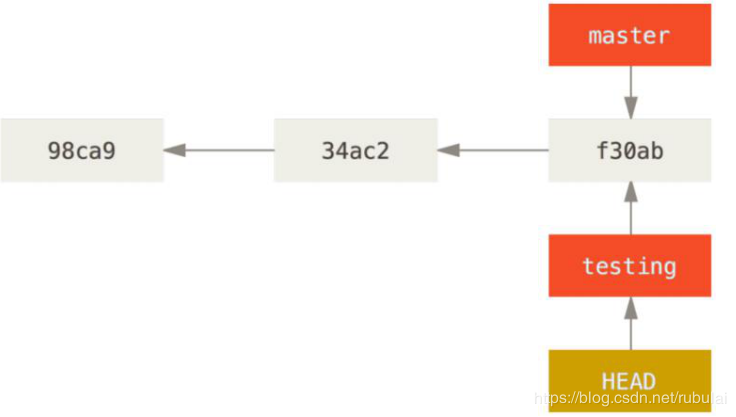
说明:切换分支时,仅仅是切换一下HEAD指针的指向,从原分支指向想切换的分支
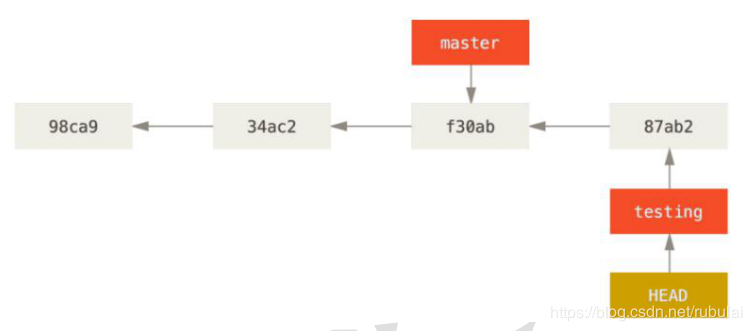
说明:若此时在testing分支上提交了版本,则只会使该分支的指针向后移动,不会影响其他分支,如上图所示,其他分支的指针指向并没有发生变化
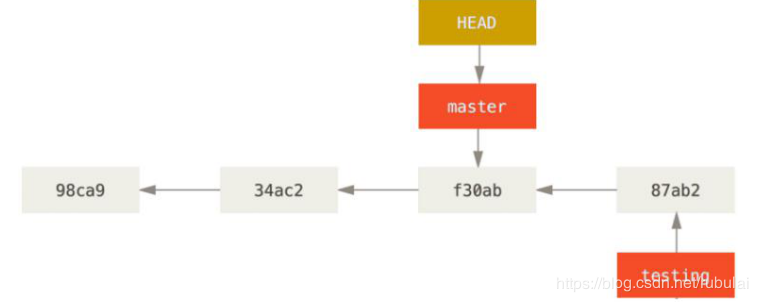
说明:在testing分支修改后,再将HEAD切换至master,然后在master上修改相同的文件,然后再master分支上提交,就会形成下面的局面:这时就有可能产生冲突,这合并版本的时候就需要解决冲突。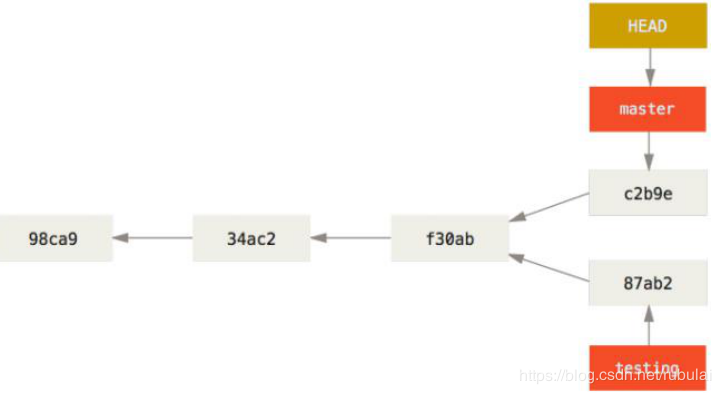
SVN在创建分支的时候是将所有文件复制一份,而git仅仅是创建一个指向当前版本的指针,因此效率很高;Git中分支之间的切换仅仅是HEAD指针的变化,效率也很高;
综上:Git的操作很依赖于HEAD指针的变化
摘要
在这段时间和队友合作写一个项目的过程中,合代码一直是我学习过程中迈不过去的大石头,绕也绕不过去的那种,这次痛定思痛决定研究一下git的原理,它的那些命令到底对应着git内部的哪些操作?它的工作原理是什么?为什么合并冲突有时候把我自己本地的代码毁掉了?如何正确高效地合并冲突?开发的时候应该如何进行多人合作?它的哪些好用的命令我还没有使用过?
下面我将就以下几个方面来完成这次分享。
此外由于时间原因,以下的一些内容没有涉及到,但是在后续学习过程中会完善博客内容。
目录
git是一种分布式版本控制系统
版本控制这个说法多少有一点抽象。事实上,版本控制这件事儿我们一直在做,只是平时不这么称呼。举一个栗子,boss让你写一个策划案,你先完成了一稿,之后又有了一些新的想法,但是并不确定新的想法是否能得到boss的认可,于是你保存了一个初稿,之后在初稿的基础上另存了一个文件,做了部分修改完成了一个修改稿。OK,这时你的策划案就有了两个版本——初稿和修改稿。如果boss对修改稿不满意,你可以很轻易的把初稿拿出来交差。
在这个简单的过程中,你已经执行了一个简单的版本控制操作——把文档保存为初稿和修改稿的过程就是版本控制。
学术点说,版本控制就是对文件变更过程的管理。说白了,版本控制就是要把一个文件或一些文件的各个版本按一定的方式管理起来,目的是需要用到某个版本的时候可以随时拿出来
这里的“分布式”是相对于“集中式”来说的。把数据集中保存在服务器节点,所有的客户节点都从服务节点获取数据的版本控制系统叫做集中式版本控制系统,比如svn就是典型的集中式版本控制系统。
与之相对,Git的数据不止保存在服务器上,同时也完整的保存在本地计算机上,所以我们称Git为分布式版本控制系统。
Git的这种特性带来许多便利,比如你可以在完全离线的情况下使用Git,随时随地提交项目更新,而且你不必为单点故障过分担心,即使服务器宕机或数据损毁,也可以用任何一个节点上的数据恢复项目,因为每一个开发节点都保存着完整的项目文件镜像。
在未接触版本控制系统之前,很多人会通过保存项目或文件的备份来达到版本控制的目的。通常你的文件或文件夹名会设置成“XXX-v1.0”、“XXX-v2.0”等。
这是一种简单的办法,但过于简单。这种方式无法详细记录版本附加信息,难以应付复杂项目或长期更新的项目,缺乏版本控制约定,对协作开发无能为力。如果你不慎使用了这种方式,那么稍稍过一段时间你就会发现连自己都不知道每个版本间的区别,版本控制形同虚设。
pull request操作来通知其他团队成员,其他团队成员能够review code后再合并代码。诸如此类,数不胜数。然而实现这些功能的基础是对文件变更过程的存储。
所以,如果问“Git能够解决哪些问题?”我们可以简单的回答:Git解决了版本控制方面的很多问题,但最核心的是它很好的解决了版本状态存储(即文件变更过程存储)的问题。
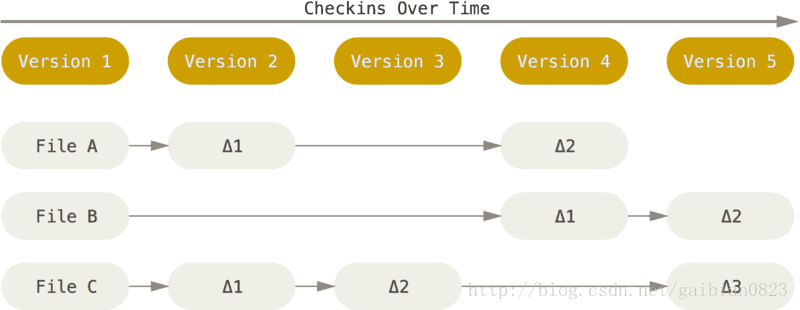
Git 和其它版本控制系统(包括 Subversion 和近似工具)的主要差别在于 Git 对待数据的方法。 概念上来区分,其它大部分系统以文件变更列表的方式存储信息。 这类系统(CVS、Subversion、Perforce、Bazaar 等等)将它们保存的信息看作是一组基本文件和每个文件随时间逐步累积的差异。存储每个文件与初始版本的差异,如下图所示 -
Git 不按照以上方式对待或保存数据。 反之,Git 更像是把数据看作是对小型文件系统的一组快照。 每次提交更新,或在 Git 中保存项目状态时,它主要对当时的全部文件制作一个快照并保存这个快照的索引。 为了高效,如果文件没有修改,Git 不再重新存储该文件,而是只保留一个链接指向之前存储的文件。 Git 对待数据更像是一个 快照流。如下图所示 -
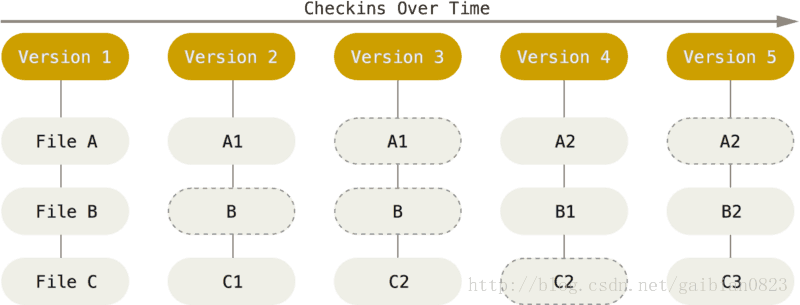
这是 Git 与几乎所有其它版本控制系统的重要区别。 因此 Git 重新考虑了以前每一代版本控制系统延续下来的诸多方面。 Git 更像是一个小型的文件系统,提供了许多以此为基础构建的超强工具,而不只是一个简单的 VCS。 稍后我们在 Git 分支讨论 Git 分支管理时,将探究这种方式对待数据所能获得的益处。
在 Git 中的绝大多数操作都只需要访问本地文件和资源,一般不需要来自网络上其它计算机的信息。 如果你习惯于所有操作都有网络延时开销的集中式版本控制系统,Git 在这方面会让你感到速度之神赐给了 Git 超凡的能量。 因为你在本地磁盘上就有项目的完整历史,所以大部分操作看起来瞬间完成。
举个例子,要浏览项目的历史,Git 不需外连到服务器去获取历史,然后再显示出来——它只需直接从本地数据库中读取。 你能立即看到项目历史。 如果想查看当前版本与一个月前的版本之间引入的修改,Git 会查找到一个月前的文件做一次本地的差异计算,而不是由远程服务器处理或从远程服务器拉回旧版本文件再来本地处理。
这也意味着你离线或者没有 VPN 时,几乎可以进行任何操作。 如你在飞机或火车上想做些工作,你能愉快地提交,直到有网络连接时再上传。 如你回家后 VPN 客户端不正常,你仍能工作。 使用其它系统,做到如此是不可能或很费力的。 比如,用 Perforce,你没有连接服务器时几乎不能做什么事;用 Subversion 和 CVS,你能修改文件,但不能向数据库提交修改(因为你的本地数据库离线了)。 这看起来不是大问题,但是你可能会惊喜地发现它带来的巨大的不同。
Git 中所有数据在存储前都计算校验和,然后以校验和来引用。 这意味着不可能在 Git 不知情时更改任何文件内容或目录内容。 这个功能建构在 Git 底层,是构成 Git 哲学不可或缺的部分。 若你在传送过程中丢失信息或损坏文件,Git 就能发现。
你执行的 Git 操作,几乎只往 Git 数据库中增加数据。 很难让 Git 执行任何不可逆操作,或者让它以任何方式清除数据。 同别的 VCS 一样,未提交更新时有可能丢失或弄乱修改的内容;但是一旦你提交快照到 Git 中,就难以再丢失数据,特别是如果你定期的推送数据库到其它仓库的话。
这使得我们使用 Git 成为一个安心愉悦的过程,因为我们深知可以尽情做各种尝试,而没有把事情弄糟的危险。 更深度探讨 Git 如何保存数据及恢复丢失数据的话题,请参考撤消操作。
目录
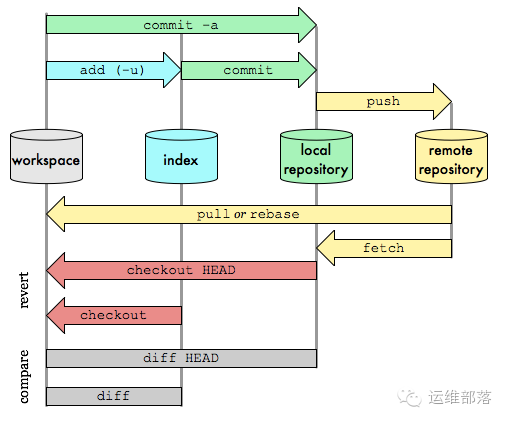
从时间先后来讲:
远程仓库是本地仓库的异地备份,远程仓库的内容可能被分布在多个地点的处于协作关系的本地仓库 修改,因此它可能与本地仓库同步,也可能不同步,但是它的内容是最旧的。
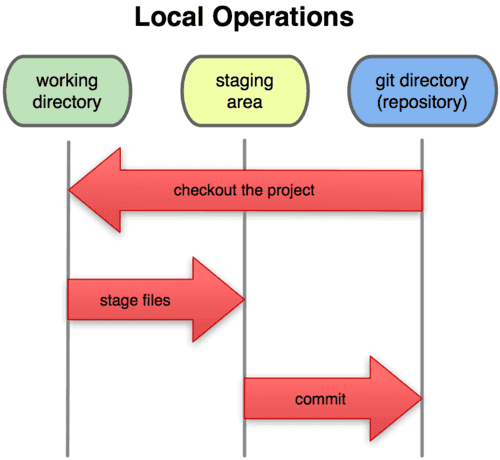
任何对象都是在工作目录中诞生和被修改;
图最上方的 add、commit、push等,展示了git仓库的产生过程。反过来,我们可以从远程历史仓库中获得本地仓库的最后一个版本,clone到本地,从本 地检出对象的各个版本到index暂存区或工作目录中,从而实现任何对象或整个仓库的任意阶段状态的”回滚”。
一开始接触这些概念可能比较绕,其实在git入门阶段,可以先抛开远程仓库不看,只了解管理本地仓库的”3棵树”就够了。如下图:
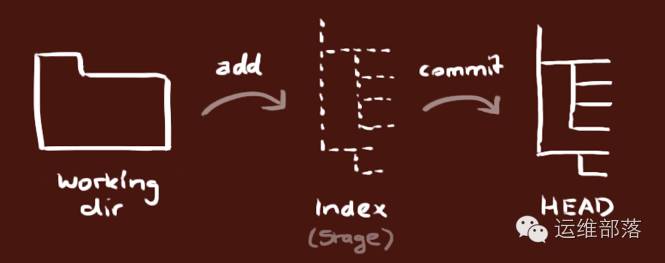
对任何一个文件,在git内都有三种状态:
我们可以从文件所处的位置来判断状态:
1 | git init |
指令解释
git init 表示在当前的项目目录中生成本地的git管理;
git add README.md 将“README.md”文件保存至缓存区;
git commit -m "first commit" 将代码从缓存区保存至本地仓库;
git remote add origin https://github.com/wteam-xq/testGit.git将本地仓库与指定的远程仓库创建 联系;
push -u origin master 将本地仓库代码推送至远程仓库
原理图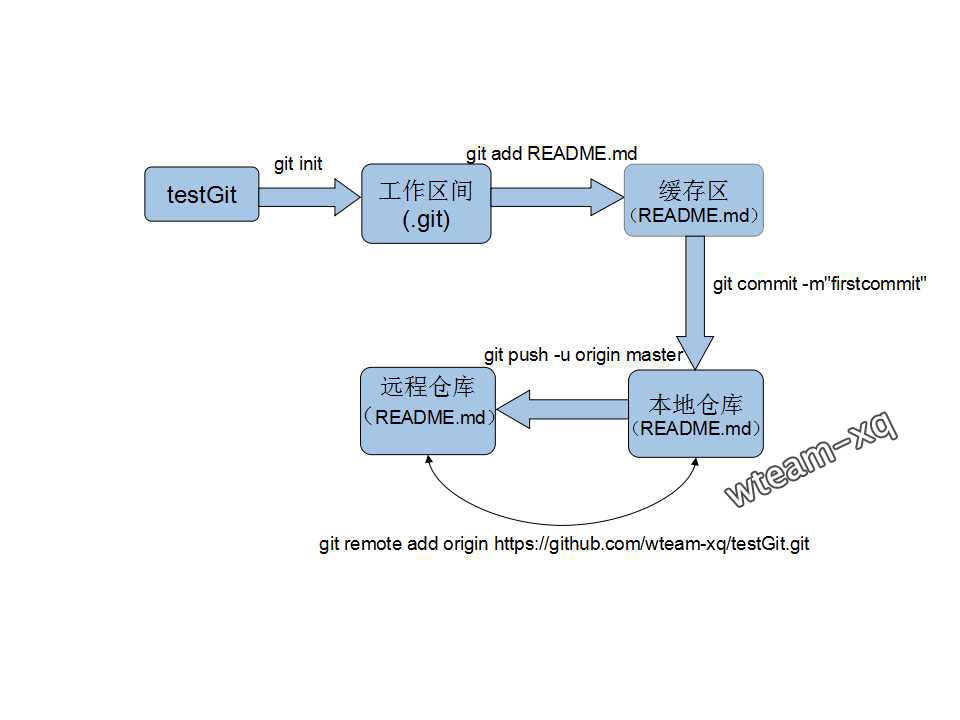
首先我们新建一文件夹:copyTestGit,进入该文件夹后使用git 指令:1
git clone
指令执行完毕后, 就在该文件夹下生成一份副本啦
原理图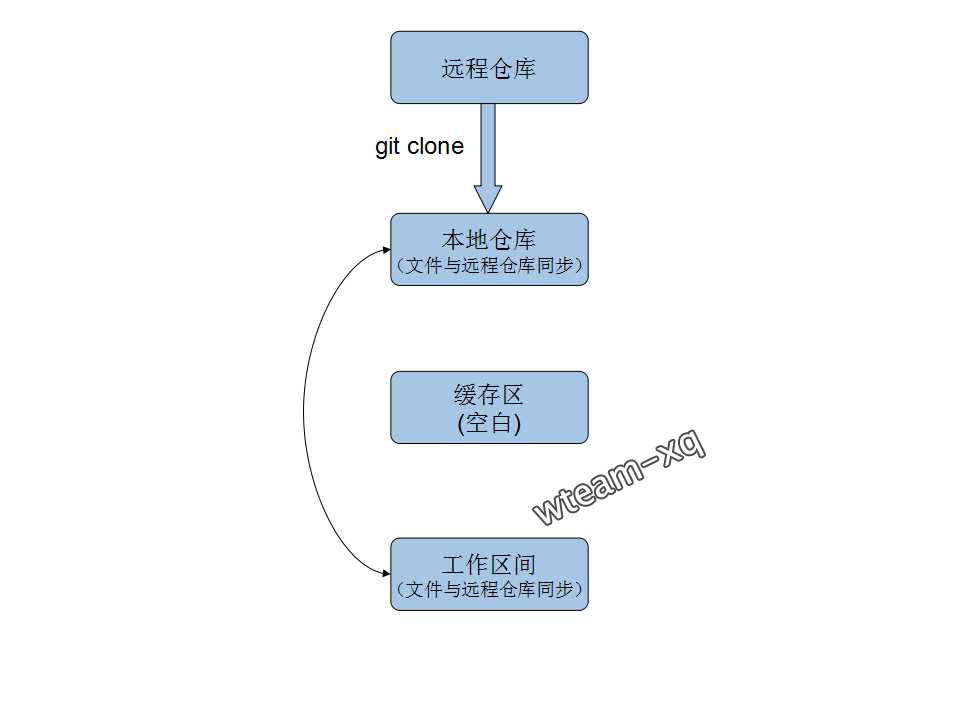
接下来, 讨论git pull、 git fetch 、 git merge的关系
先抛简单结论:
1 | git pull |
等同于下面命令1
2git fetch
git merge
实际项目:我们在testGit工程中修改README.md,然后更新、提交下代码 执行以下git 指令(日常使用中会用git status看看是否有文件需要git add):1
2git commit -am 'update readme.md'
git push origin master
原理图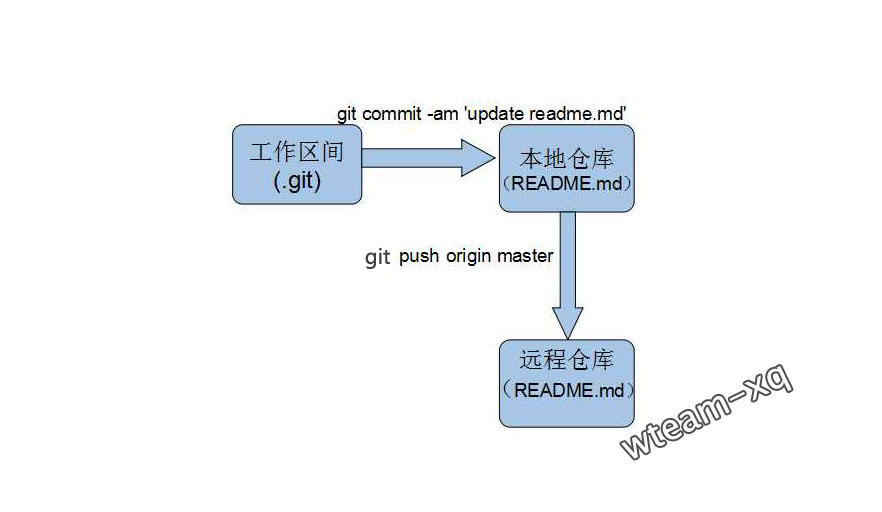
远程仓库代码更新后, 我们进入另一本地仓库:copyTestGit\testGit,将远程仓库的代码更新至该本地仓库。
在该目录下输入以下git指令:1
2git fetch
git merge origin/master
以上指令别的原理图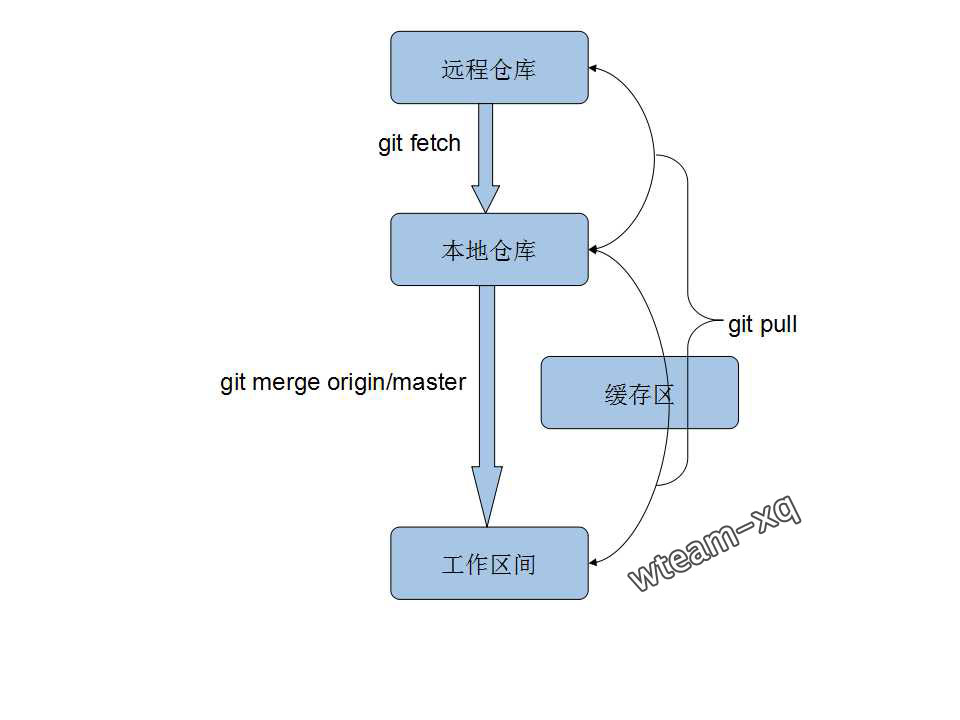
首先在本地修改文件,现在副本工程修改完了代码打算提交,提交前先将远程仓库最新代码更新至本地仓库, 惯例使用指令:1
git pull
指令执行之后会发现以下冲突提示: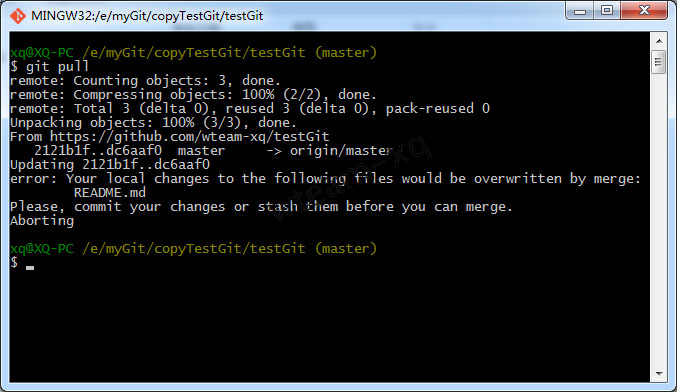
出现以上提示, 说明本次更新代码失败;主要在于本地工作区间跟远程仓库的新代码冲突了, 图解如下: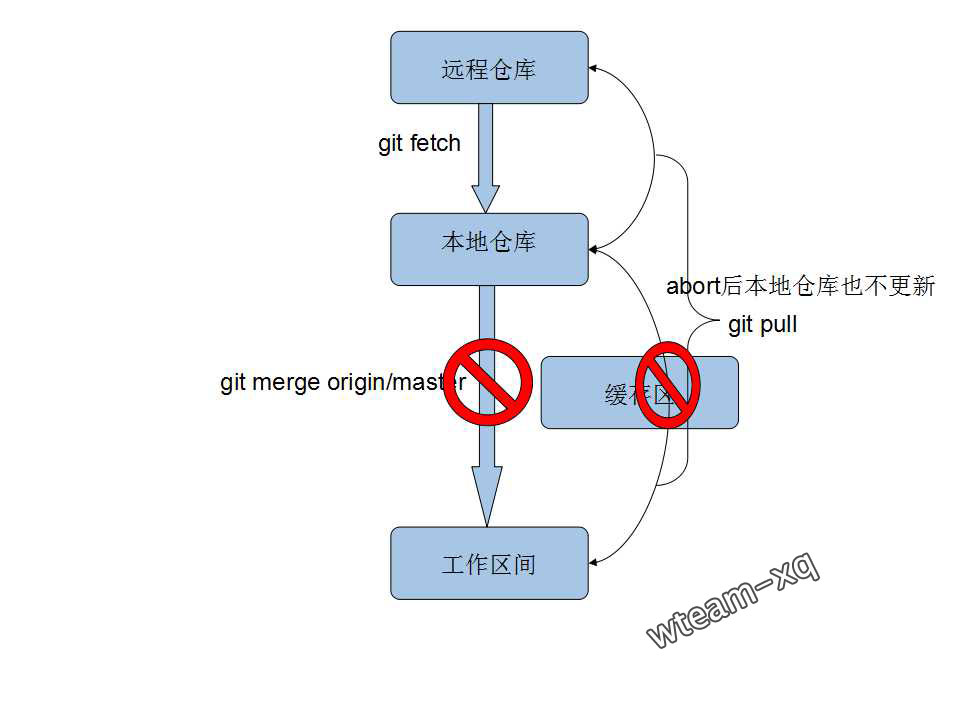
接下来,有两种方式处理冲突: 放弃本地修改或 解决冲突后提交本地修改
放弃本地修改意味着将远程仓库的代码完全覆盖本地仓库以及本地工作区间, 如果对git的指令不熟悉那大可以将本地工程完全删除,然后再重新拷贝一次(git clone)。
当然, git如此强大没必要用这么原始的方法,可以让本地仓库代码覆盖本地修改,然后更新远程仓库代码;
本地仓库代码完全覆盖本地工作区间,具体指令如下:1
git checkout head .
(注意: 别遗漏 “head” 后的 “ .” )
然后更新远程仓库的代码就不会出现冲突了:1
git pull
原理图如下: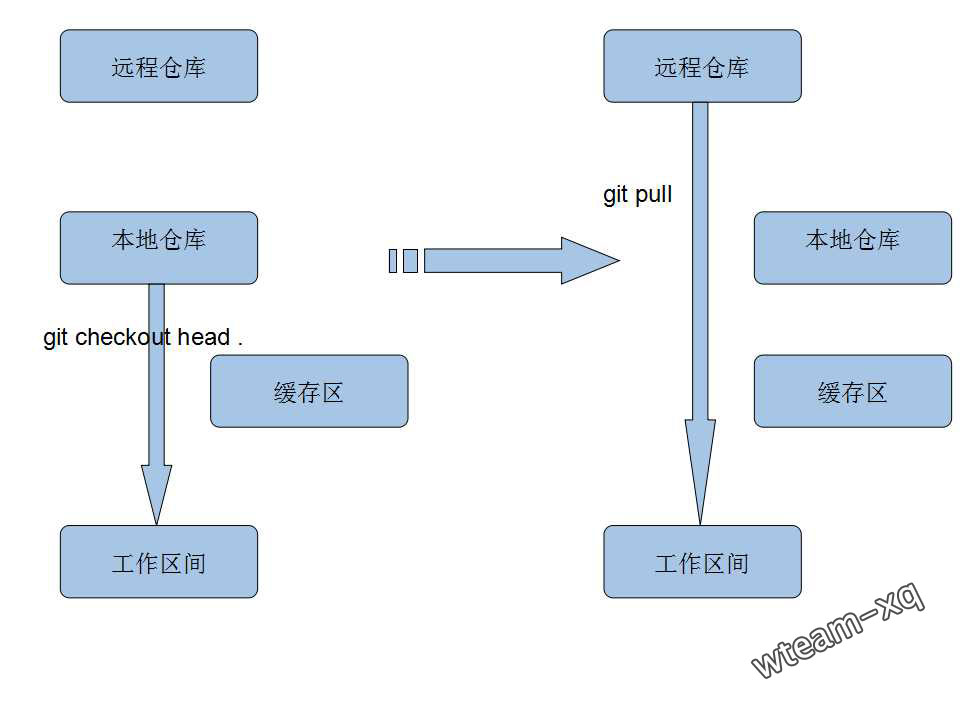
缓存区 除了开始出现外,后续提交代码、更新代码篇章都在打酱油;终于,这次冲突解决事件, 它将会是主角!
解决冲突后提交本地修改的思路大概如下:
将本地修改的代码放在缓存区, 然后从远程仓库拉取最新代码,拉取成功后再从缓存区将修改的代码取出, 这样最新代码跟本地修改的代码就会混杂在一起, 手工解决冲突后, 提交解决冲突后的代码。
原理图: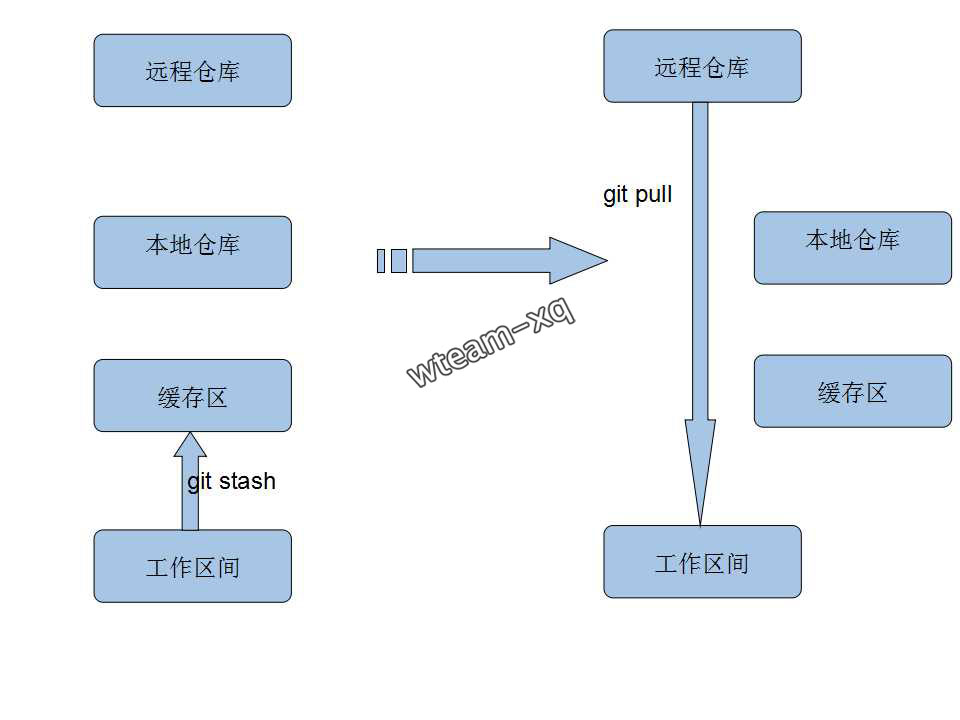
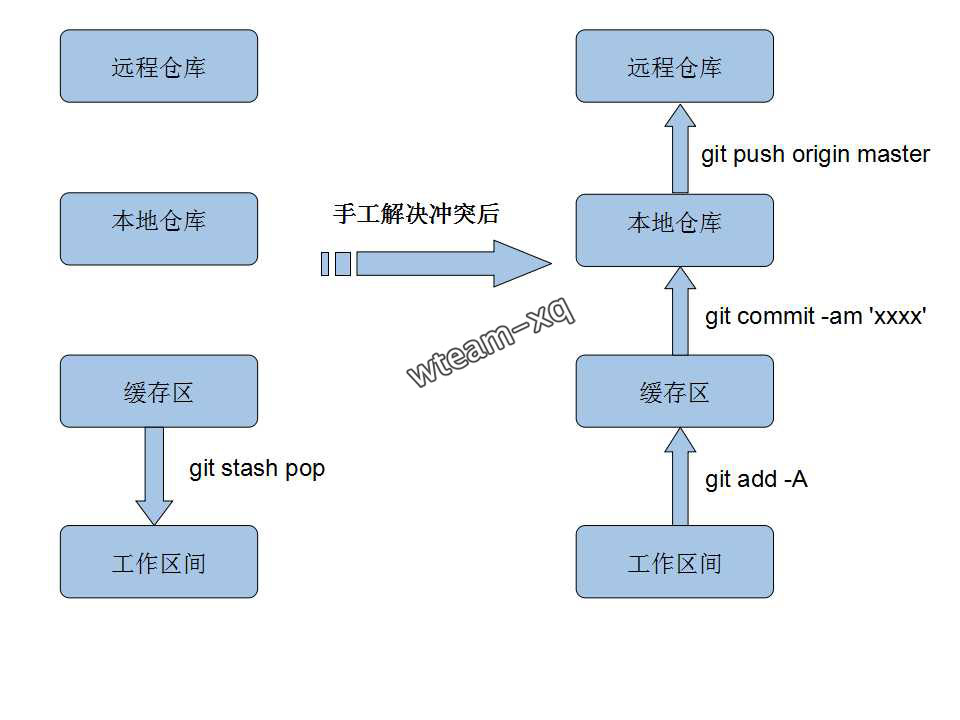
对应到我们实际项目中, 进入 copyTestGit/testGit 执行指令git pull出现 (重回到上述冲突场景)1
2
3
4error: Your local changes to the following files would be overwritten by merge:
README.md
Please, commit your changes or stash them before you can merge.
Aborting
将本地修改放入缓存区(成功后本地工作区间的代码跟本地仓库代码会同步), 具体指令:1
git stash
从远程仓库获取最新代码,具体指令:1
git pull
然后, 取出本地修改的代码, 具体指令:1
git stash pop
然后, git 自动合并冲突失败, 冲突的代码就很清晰的展现在我们面前了,手动解决冲突之后告诉git, 这个文件(README.md)的冲突 已经解决:1
git add README.md
提交代码(细节参考前述流程):1
2git commit -am '终于解决冲突啦!'
git push origin master
于是本地有冲突的代码就提交成功啦!
在基于以上案例的基础上,我们可以总结出git工作的大致过程,具体内容参见另一篇博文
目录
在了解git分支的具体分类及使用之前,先要了解一下git分支管理机制,具体内容参见另一篇博文
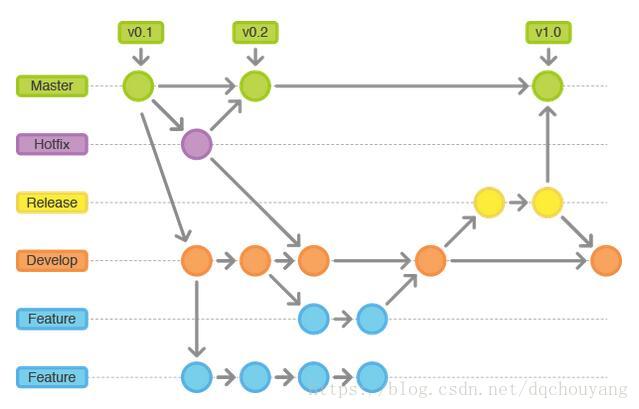
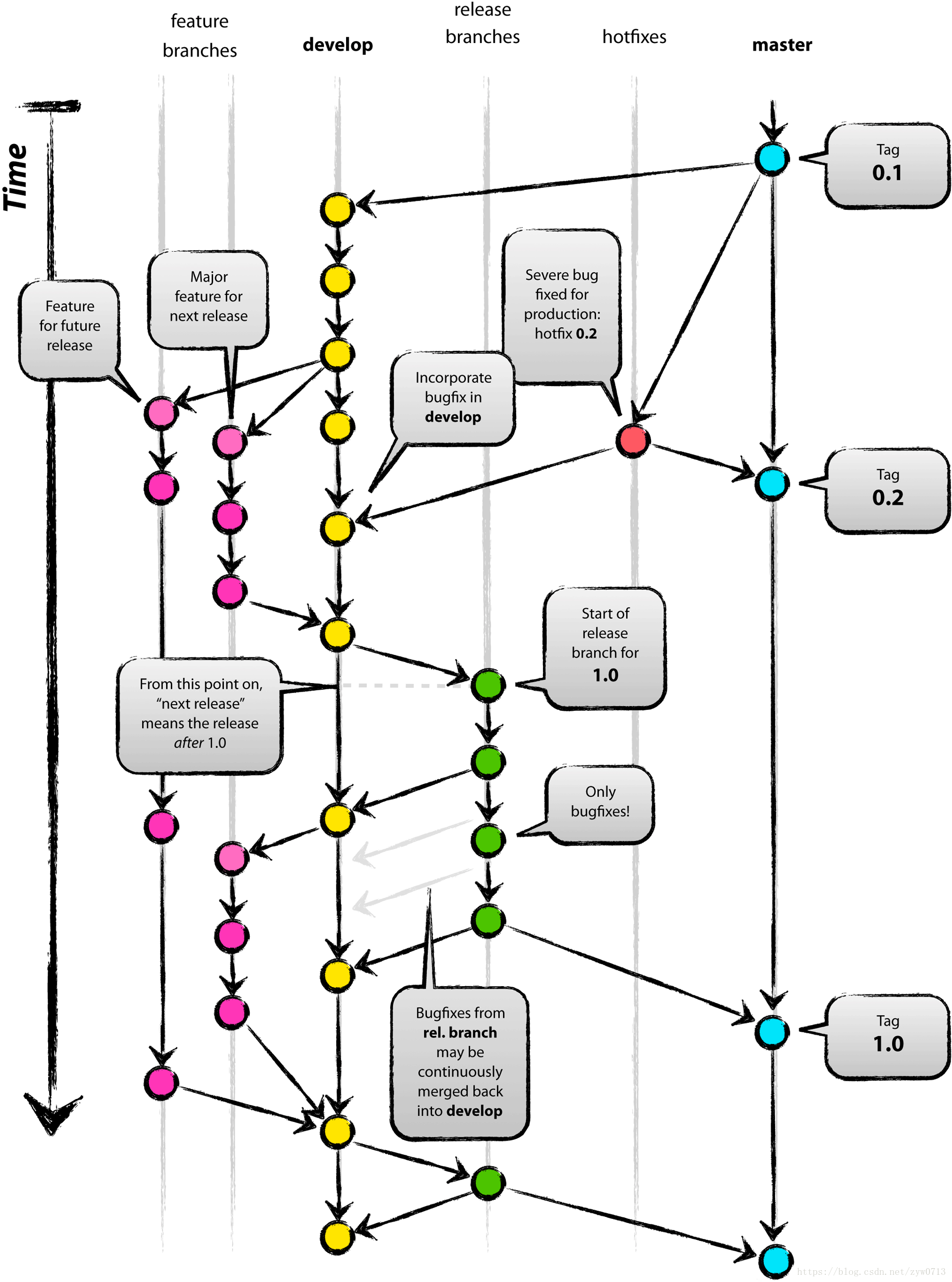
代码库应该有且只有一个主分支。所有提供给用户使用的正式版本,都在这个主分支上发布。
Git主分支的名字,默认叫做Master。它是自动建立的,版本库初始化以后,默认就是在主分支在进行开发。
主分支只用来分布重大版本,日常开发应该在另一条分支上完成。我们把开发用的分支,叫做Develop。
这个分支可以用来生成代码的最新隔夜版本(nightly)。如果想正式对外发布,就在Master分支上,对Develop分支进行”合并”(merge)。
Git创建Develop分支的命令1
git checkout -b develop master
将Develop分支发布到Master分支的命令
1 | git checkout master |
–no-ff参数:默认情况下,Git执行”快进式合并”,会直接将Master分支指向Develop分支。强推。少用!!
前面讲到版本库的两条主要分支:Master和Develop。前者用于正式发布,后者用于日常开发。其实,常设分支只需要这两条就够了,不需要其他了。
但是,除了常设分支以外,还有一些临时性分支,用于应对一些特定目的的版本开发。临时性分支主要有三种:
功能分支 (feature)
预发布分支 (release)
修补bug分支 (fixbug)
这三种分支都属于临时性需要,使用完以后,应该删除,使得代码库的常设分支始终只有Master和Develop。
为了开发某种特定功能,从Develop分支上面分出来的。开发完成后,要再并入Develop。
功能分支的名字,可以采用feature-*的形式命名。
创建一个功能分支1
git checkout -b feature-x develop
合并到develop分支
1 | git checkout develop |
删除feature分支1
git branch -d feature-x
指发布正式版本之前(即合并到Master分支之前),我们可能需要有一个预发布的版本进行测试。
预发布分支是从Develop分支上面分出来的,预发布结束以后,必须合并进Develop和Master分支。它的命名,可以采用release-*的形式。
创建一个预发布分支:1
git checkout -b release-x develop
确认没有问题后,合并到master分支:1
2git checkout master
git merge --no-ff release-x
对合并生成的新节点,做一个标签1
git tag -a x
再合并到develop分支1
2git checkout develop
git merge --no-ff release-x
最后记得删除预发布分支:1
git branch -d release-x
软件正式发布以后,难免会出现bug。这时就需要创建一个分支,进行bug修补。
修补bug分支是从Master分支上面分出来的。修补结束以后,再合并进Master和Develop分支。它的命名,可以采用fixbug-*的形式。
创建一个修补bug分支:1
git checkout -b fixbug-xx master
修补结束后,合并到master分支:1
2
3git checkout master
git merge --no-ff fixbug-xx
git tag -a xx
再合并到develop分支:1
2git checkout develop
git merge --no--ff fixbug-xx
最后,删除”修补bug分支”:1
git branch -d fixbug-xx
在基于以上对文件在被git管理过程中所处的四个阶段、三种状态以及多种分支的功能作用以及原理的了解下,可以学习多人合作共同开发的工作流程了。
参考文章1:git多人协作工作流程
Git 多人协作开发的过程
深入理解Git的实现原理
git 的工作流程(纯干货)
git工作原理
git原理图解
Git的思想和基本工作原理2
Git 思想和工作原理
Git——基本原理
在前端的工作学习中,我们有可能会遇到以下问题,比如图片无法加载、样式不正确、JS无法执行、无法调至手机页面、与后台对接出错等等问题,在排查和处理这些问题的方法就是使用浏览器的开发者工具。

首先红色区域内从左到右依次为:
绿色区域:
千万注意!!!打开windows终端之后默认的目录是C:/Users/hp,但是我在官网上下载的node保存在D:/Program Files/nodejs里面,设置环境变量的时候设置的是node,导致cnpm -v总出现不是内部命令的提示,实际上就是因为cnpm没有设置好环境变量!!!
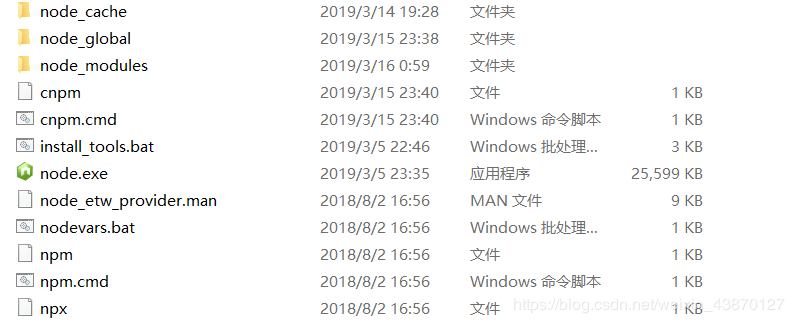
理想状态下的nodejs文件夹是这样的,保存npm和npm.cmd,以及cnpm和cnpm.cmd这两种后缀名的文件,包括我下载的别的内容也如此: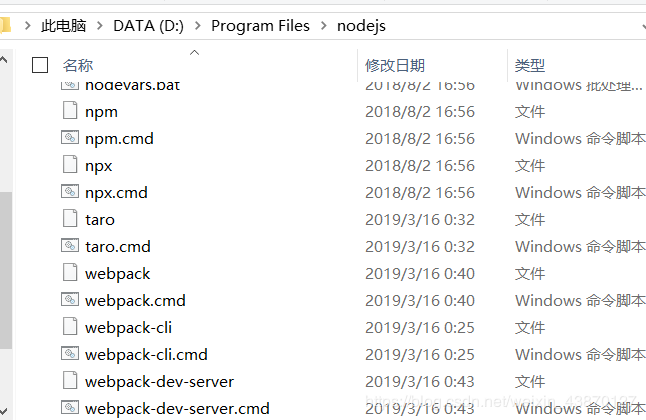
包括文件本身及其.cmd后缀文件,然后它们相应的的文件夹保存在node_modules文件夹中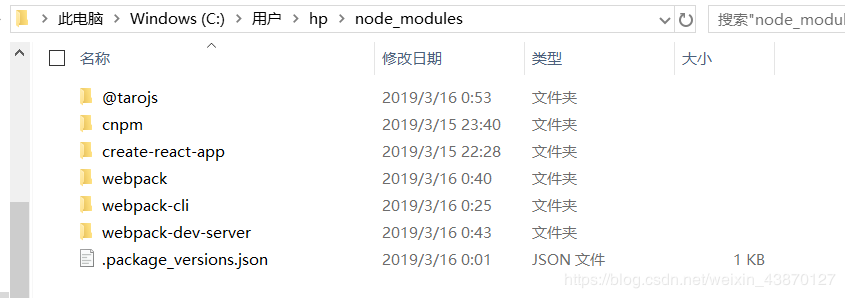
所以重新下载了它要求的版本,然后继续提升webpack-dev-server版本过低,所以也重新下载了它要求的版本。然后才能够运行
taro安装项目依赖失败后手动安装npm install也不行,解决方法是安装cnpm
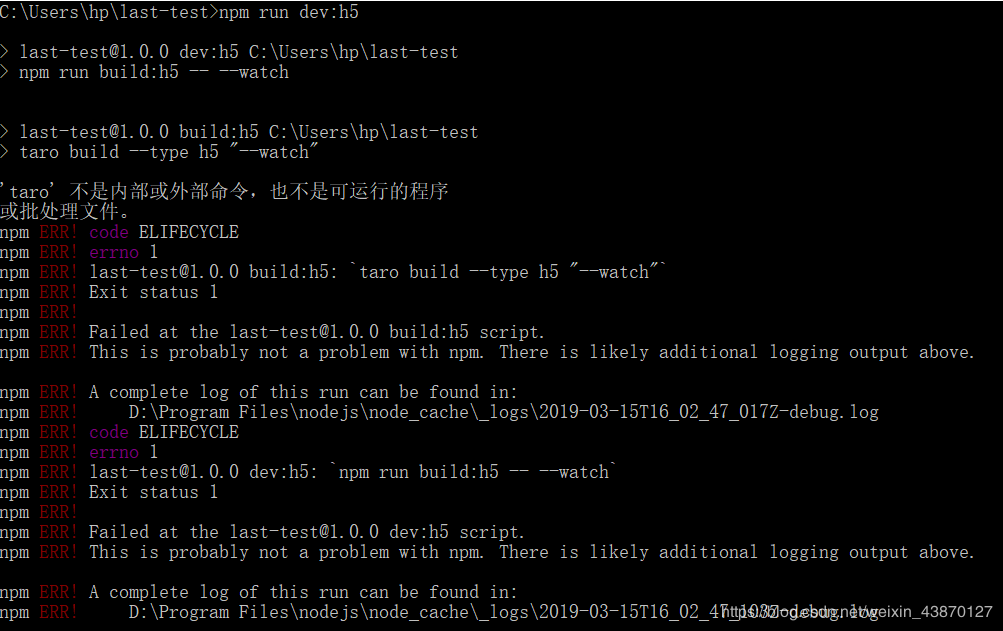
关注taro不是内部命令,由前几次安装cnpm失败可知这是taro设置全局变量不成功,所以就有了上面nodejs文件夹里的格式,再windows上安装这些东西,最大的坑就是要设置全局变量,然后设置错误啊!!!!= = 有的人不需要设置系统直接给出了,有的倒霉蛋比如我就得一个一个设置,总而言之安装上方nodejs的文件夹格式是可以设置成功的
taro其实和react安装差不多,但是可能是taro它比较新所以不完善吗???它的错误提示一点都不明确,都是一些看不懂的内容,幸亏我是react、taro一起下,出现了同样看不懂的内容,react还提示了我看得懂的内容,比如我要下载Python,比如我webpack和webpack-dev-server版本不对等等。